1. Introduction
Kaitai Struct is a domain-specific language (DSL) that is designed with one particular task in mind: dealing with arbitrary binary formats.
Parsing binary formats is hard, and there’s a reason for that: such formats were designed to be machine-readable, not human-readable. Even when one’s working with a clean, well-documented format, there are multiple pitfalls that await the developer: endianness issues, in-memory structure alignment, variable size structures, conditional fields, repetitions, fields that depend on other fields previously read, etc, etc, to name a few.
Kaitai Struct tries to isolate the developer from all these details and allow them to focus on the things that matter: the data structure itself, not particular ways to read or write it.
2. Installation and invocation
Kaitai Struct has a somewhat diverse infrastructure around it. This chapter will give an overview of the options available.
2.1. Web IDE
If you’re going to try Kaitai Struct for the first time, the Web IDE is probably the easiest way to get started. Just open Kaitai Struct Web IDE and you’re ready to go:
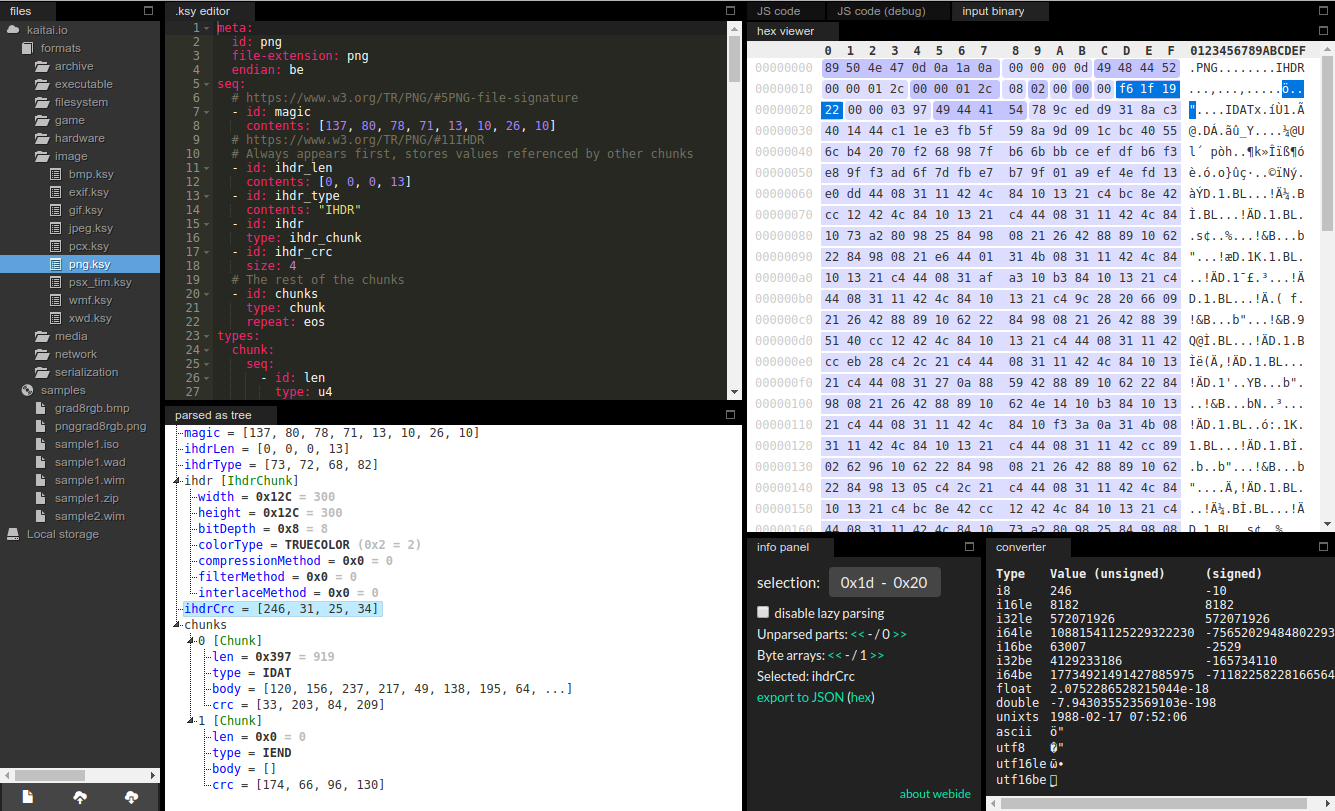
A list of Web IDE features is available on the kaitai_struct_webide GitHub wiki.
Note that there are two different versions of the Web IDE:
-
https://ide.kaitai.io/ — stable version, has the stable Kaitai Struct compiler (currently 0.11, released 2025-09-07)
-
https://ide.kaitai.io/devel/ — unstable development version, has the latest compiler (the most recent 0.12-SNAPSHOT)
If you want to use the latest features, use the devel Web IDE.
|
Note
|
The devel Web IDE follows the default
master branch
of the kaitai_struct_webide
repository — it is automatically updated when the
master branch
is updated.
|
2.2. Desktop / console version
If you don’t fancy using a hex dump in a browser, or want to integrate Kaitai Struct into your project build process automation, you’d want a desktop / console solution. Of course, Kaitai Struct offers that as well.
2.2.1. Installation
Please refer to the official website for installation instructions. After installation, you will have:
-
ksc(orkaitai-struct-compiler) — command-line Kaitai Struct compiler, a program that translates.ksyinto parsing libraries in a chosen target language. -
ksv(orkaitai-struct-visualizer, optional) — console visualizer
|
Note
|
ksc or ksv shorthand might be not available if your system doesn’t
support symbolic links — just use the full name in that case.
|
If you’re going to invoke ksc frequently, you’d probably want to add
it to your executable searching PATH, so you don’t have to type the full
path to it every time. You’d get that automatically on .deb package
and Windows .msi install (provided you don’t disable that option) -
but it might take some extra manual setup if you use a generic .zip
package.
2.2.2. Invocation
Invoking ksc is easy:
ksc [options] <file>...Common options:
-
<file>…— source files (.ksy) -
-t <language> | --target <language>— target languages (cpp_stl,csharp,java,javascript,perl,php,python,ruby,all)-
allis a special case: it compiles all possible target languages, creating language-specific directories (as per language identifiers) inside output directory, and then creating output module(s) for each language starting from there
-
-
-d <directory> | --outdir <directory>— output directory (filenames will be auto-generated)
Language-specific options:
-
--dotnet-namespace <namespace>— .NET namespace (C# only, default: Kaitai) -
--java-package <package>— Java package (Java only, default: root package) -
--php-namespace <namespace>— PHP namespace (PHP only, default: root package)
Misc options:
-
--verbose— verbose output -
--help— display usage information and exit -
--version— display version information and exit
3. Workflow overview
The main idea of Kaitai Struct is that you create a description of a binary data
structure format using a formal language, save it as a .ksy file, and
then compile it with the Kaitai Struct compiler into a target programming language.
TODO
4. Kaitai Struct language
With the workflow issues out of the way, let’s concentrate on the Kaitai Struct language itself.
4.1. Fixed-size structures
Probably the simplest thing Kaitai Struct can do is reading fixed-size structures. You might know them as C struct definitions — consider something like this fictional database entry that keeps track of dog show participants:
struct {
char uuid[16]; /* 128-bit UUID */
char name[24]; /* Name of the animal */
uint16_t birth_year; /* Year of birth, used to calculate the age */
double weight; /* Current weight in kg */
int32_t rating; /* Rating, can be negative */
} animal_record;And here is how it would look in .ksy:
meta:
id: animal_record
endian: be
seq:
- id: uuid
size: 16
- id: name
type: str
size: 24
encoding: UTF-8
- id: birth_year
type: u2
- id: weight
type: f8
- id: rating
type: s4It’s a YAML-based format,
plain and simple. Every .ksy file is a type description. Everything
starts with a meta section: this is where we specify top-level info on
the whole structure we describe. There are two important things here:
-
idspecifies the name of the structure -
endianspecifies default endianness:-
befor big-endian (AKA "network byte order", AKA Motorola, etc) -
lefor little-endian (AKA Intel, AKA VAX, etc)
-
With that out of the way, we use a seq element with an array (ordered
sequence of elements) in it to describe which attributes this structure
consists of. Every attribute includes several keys, namely:
-
idis used to give the attribute a name -
typedesignates the attribute type:-
no type means that we’re dealing with just a raw byte array;
sizeis to be used to designate number of bytes in this array -
s1,s2,s4,u1,u2,u4, etc for integers-
"s" means signed, "u" means unsigned
-
number is the number of bytes
-
if you need to specify non-default endianness, you can force it by appending
beorle— i.e.s4be,u8le, etc
-
-
f4andf8for IEEE 754 floating point numbers;4and8, again, designate the number of bytes (single or double precision)-
if you need to specify non-default endianness, you can force it by appending
beorle— i.e.f4be,f8le, etc
-
-
stris used for strings; that is almost the same as "no type", but a string has a concept of encoding, which must be specified usingencoding
-
The YAML-based syntax might look a little more verbose than C-like structs, but there are a few good reasons to use it. It is consistent, it is easily extendable, and it’s easy to parse, so it’s easy to make your own programs/scripts that work with .ksy specs.
4.2. Docstrings
A very simple example is that we can add docstrings to every attribute, using syntax like that:
- id: rating
type: s4
doc: Rating, can be negativeThese docstrings are not just the comments in the .ksy file, they’ll actually get exported into the target language as well (for example, in Java they’ll become JavaDoc, in Ruby they’ll become RDoc/YARD, etc). This, in turn, is super helpful when editing the code in various IDEs that will generate reminder popups for intelligent completion, when you browse through class attributes:
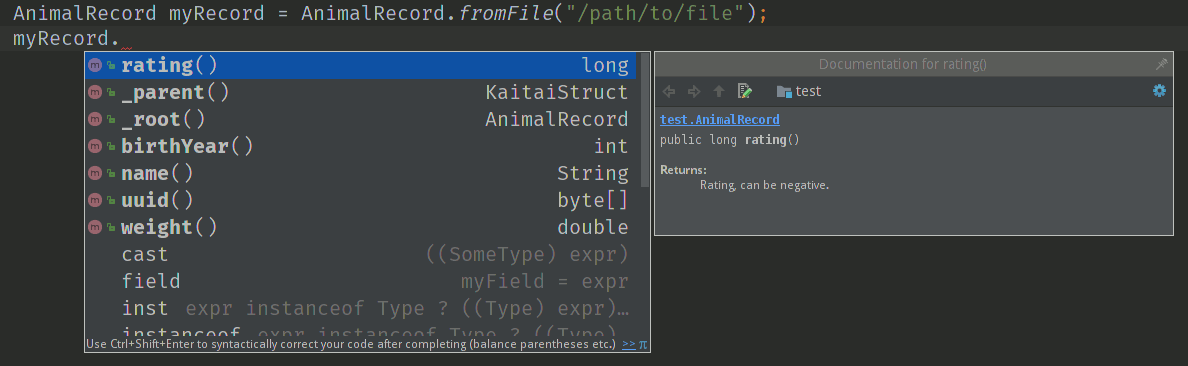
doc|
Note
|
You can use YAML folded style strings for longer documentation that spans multiple lines: |
4.3. Checking for "magic" signatures
Many file formats use some sort of safeguard measure against using a completely different file type in place of the required file type. The simple way to do so is to include some "magic" bytes (AKA "file signature"): for example, checking that the first bytes of the file are equal to their intended values provides at least some degree of protection against such blunders.
To specify "magic" bytes (i.e. fixed content) in structures, Kaitai Struct includes
a special contents key. For example, this is the beginning of a seq
for Java .class files:
seq:
- id: magic
contents: [0xca, 0xfe, 0xba, 0xbe]This reads the first 4 bytes and compares them to the 4 bytes CA FE BA BE. If
there is any mismatch (or less than 4 bytes are read),
it throws an exception and stops parsing at an early stage, before any
damage (pointless allocation of huge structures, waste of CPU cycles)
is done.
Note that contents is very flexible and you can specify:
-
A UTF-8 string — bytes from such a string would be checked against
-
An array with:
-
bytes in decimal representation
-
bytes in hexadecimal representation, starting with 0x
-
UTF-8 strings
-
In the case of using an array, all elements' byte representations would be concatenated and expected in sequence. Some examples:
- id: magic1
contents: JFIF
# expects bytes: 4A 46 49 46
- id: magic2
# we can use YAML block-style arrays as well
contents:
- 0xca
- 0xfe
- 0xba
- 0xbe
# expects bytes: CA FE BA BE
- id: magic3
contents: [CAFE, 0, BABE]
# expects bytes: 43 41 46 45 00 42 41 42 45More extreme examples to illustrate the idea (i.e. possible, but definitely not recommended in real-life specs):
- id: magic4
contents: [foo, 0, A, 0xa, 42]
# expects bytes: 66 6F 6F 00 41 0A 2A
- id: magic5
contents: [1, 0x55, '▒,3', 3]
# expects bytes: 01 55 E2 96 92 2C 33 03|
Note
|
There’s no need to specify type or size for fixed contents
data — it all comes naturally from the contents.
|
4.4. Validating attribute values
|
Important
|
Feature available since v0.9. |
To ensure attributes in your data structures adhere to expected formats
and ranges, Kaitai Struct provides a mechanism for validating attribute
values using the valid key. This key allows you to define constraints
for values, enhancing the robustness of your specifications. Here’s how
you can enforce these constraints:
-
eq(or directlyvalid: value): ensures the attribute value exactly matches the given value. -
min: specifies the minimum valid value for the attribute. -
max: specifies the maximum valid value for the attribute. -
any-of: defines a list of acceptable values, one of which the attribute must match. -
expr: an expression that evaluates to true for the attribute to be considered valid.
For most cases, the direct valid: value shortcut is preferred for its simplicity, effectively functioning as valid/eq.
seq:
# Full form of equality constraint: the only valid value is 0x42
- id: exact_value1
type: u1
valid:
eq: 0x42
# Shortcut for the above: the only valid value is 0x42
- id: exact_value2
type: u1
valid: 0x42
# Value must be at least 100 and at most 200
- id: bounded_value
type: u2
valid:
min: 100
max: 200
# Value must be one of 3, 5, or 7
- id: enum_constraint_value
type: u4
valid:
any-of: [3, 5, 7]
# Value must be even
- id: expr_constraint_value
type: u4
valid:
expr: _ % 2 == 0When a value does not meet the specified criteria, Kaitai Struct raises a validation error, halting further parsing. This preemptive measure ensures the data being parsed is within the expected domain, providing a first layer of error handling.
|
Note
|
The actual implementation of validation checks is language-dependent and may vary in behavior and supported features across different target languages. |
4.5. Variable-length structures
Many protocols and file formats tend to conserve bytes, especially for strings. Sure, it’s stupid to have a fixed 512-byte buffer for a string that typically is 3-5 bytes long and only rarely can be up to 512 bytes.
One of the most common methods used to mitigate this problem is to use some integer to designate length of the string, and store only designated number of bytes in the stream. Unfortunately, this yields a variable-length structure, and it’s impossible to describe such a thing using C-style structs. However, it’s not a problem for Kaitai Struct:
seq:
- id: my_len
type: u4
- id: my_str
type: str
size: my_len
encoding: UTF-8Note the size field: we use not a constant, but a reference to a field
that we’ve just parsed from a stream. Actually, you can do much more
than that — you can use a full-blown expression language in size
field. For example, what if we’re dealing with UTF-16 strings and
my_len value designates not a number of bytes, but number of byte
pairs?
seq:
- id: my_len
type: u4
- id: my_str
type: str
size: my_len * 2
encoding: UTF-16LEOne can just multiply my_len by 2 — and voila — here’s our UTF-16
string. Expression language is very powerful, we’ll be talking more
about it later.
Last, but not least, we can specify a size that spans automatically to
the end of the stream. For that one, we’ll use a slightly different
syntax:
seq:
- id: some_int
type: u4
- id: string_spanning_to_the_end_of_file
type: str
encoding: UTF-8
size-eos: true4.6. Delimited structures
|
Note
|
All features specified in this section are demonstrated on strings, but the same features should work on any user types as well. |
Another popular way to avoid allocating huge fixed-size buffers is to use some sort of trailing delimiter. The most well-known example of this is probably the null-terminated string which became a standard string representation in C:
61 62 63 00
These 4 bytes actually represent the 3-character string "abc", plus one extra trailing byte "0" (AKA null) which serves as a delimiter or terminator. By agreement, C strings cannot include a zero byte: every time a function in C sees that either in stream or in memory, it considers that as a special mark to stop processing.
In Kaitai Struct, you can define all sorts of delimited structures. For example, this is how you define a null-terminated string:
seq:
- id: my_string
type: str
terminator: 0
encoding: UTF-8As this is a very common thing, there’s a shortcut for type: str and
terminator: 0. One can write this as:
seq:
- id: my_string
type: strz
encoding: UTF-8Of course, you can use any other byte (for example, 0xa, AKA
newline) as a terminator. This gives Kaitai Struct some limited
capabilities to parse certain text formats as well.
Reading "until the terminator byte is encountered" could be dangerous. What if we never encounter that byte?
Another very widespread model is actually having both a fixed-sized buffer for a string and a terminator. This is typically an artifact of serializing structures like this from C. For example, take this structure:
struct {
char name[16]; /* Name of the animal */
uint16_t birth_year; /* Year of birth, used to calculate the age */
} animal_record;and do the following in C:
struct animal_record rec;
strcpy(rec.name, "Princess");
// then, after some time, the same record is reused
strcpy(rec.name, "Sam");After the first strcpy operation, the buffer will look like:
50 72 69 6e|63 65 73 73|00 ?? ?? ??|?? ?? ?? ??| |Princess.???????|
And after the second strcpy, the following will remain in the
memory:
53 61 6d 00|63 65 73 73|00 ?? ?? ??|?? ?? ?? ??| |Sam.cess.???????|
Effectively, the buffer is still 16 bytes, but the only meaningful
contents it has is up to first null terminator. Everything beyond that
is garbage left over from either the buffer not being initialized at all
(these ?? bytes could contain anything), or it will contain parts of
strings previously occupying this buffer.
It’s easy to model that kind of behavior in Kaitai Struct as well,
just by combining size and terminator:
seq:
- id: name
type: str
size: 16
terminator: 0
encoding: UTF-8This works in 2 steps:
-
sizealways that exactly 16 bytes would be read from the stream. -
terminator, given thatsizeis present, only works inside these 16 bytes, cutting string short early with the first terminator byte encountered, saving application from getting all that trailing garbage.
4.7. Enums (named integer constants)
The nature of binary format encoding dictates that in many cases we’ll be using some kind of integer constants to encode certain entities. For example, an IP packet uses a 1-byte integer to encode the protocol type for the payload: 6 would mean "TCP" (which gives us TCP/IP), 17 would mean "UDP" (which yields UDP/IP), and 1 means "ICMP".
It is possible to live with just raw integers, but most programming languages actually provide a way to program using meaningful string names instead. This approach is usually dubbed "enums" and it’s totally possible to generate an enum in Kaitai Struct:
seq:
- id: protocol
type: u1
enum: ip_protocol
enums:
ip_protocol:
1: icmp
6: tcp
17: udpThere are two things that should be done to declare a enum:
-
We add an
enumskey on the type level (i.e. on the same level asseqandmeta). Inside that key, we add a map, keys of it being enum names (in this example, there’s only one enum declared,ip_protocol) and values being yet another map, which maps integer values into identifiers. -
We add an
enum: …parameter to every attribute that’s going to be represented by that enum, instead of just being a raw integer. Note that such attributes must have some sort of integer type in the first place (i.e.type: u*ortype: s*).
4.8. Substructures (subtypes)
What do we do if we need to use many of the strings in such a format?
Writing so many repetitive my_len- / my_str-style pairs would be so
bothersome and error-prone. Fear not, we can define another type,
defining it in the same file, and use it as a custom type in a stream:
seq:
- id: track_title
type: str_with_len
- id: album_title
type: str_with_len
- id: artist_name
type: str_with_len
types:
str_with_len:
seq:
- id: len
type: u4
- id: value
type: str
encoding: UTF-8
size: lenHere we define another type named str_with_len, which we reference
just by doing type: str_with_len. The type itself is defined using the
types: key at the top level. That’s a map, and inside it we can define as
many subtypes as we want. We define just one, and inside it we nest
the exact same syntax as we use for the type description on the top
level — i.e. the same seq designation.
|
Note
|
There’s no need for meta/id here, as the type name is derived from the
types key name here.
|
Of course, one can actually have more levels of subtypes:
TODO
4.9. Accessing attributes in other types
Expression language (used, for example, in a size key) allows you to
refer not only to attributes in the current type, but also in other types.
Consider this example:
seq:
- id: header
type: main_header
- id: body
size: header.body_len
types:
main_header:
seq:
- id: magic
contents: MY-SUPER-FORMAT
- id: body_len
type: u4If the body_len attribute was in the same type as body, we could just
use size: body_len. However, in this case we’ve decided to split the
main header into a separate subtype, so we’ll have to access it using the .
operator — i.e. size: header.body_len.
One can chain attributes with . to dig deeper into type
hierarchy — e.g. size: header.subheader_1.subsubheader_1_2.field_4.
But sometimes we need just the opposite: how do we access upper-level
elements from lower-level types? Kaitai Struct provides two options here:
4.9.1. _parent
One can use the special pseudo-attribute _parent to access the parent
structure:
TODO4.9.2. _root
In some cases, it would be way too impractical to write tons of
_parent._parent._parent._parent... or just plain impossible (if you’re
describing a type which might be used on several different levels, thus
different number of _parent would be needed). In this case, we can use a
special pseudo-attribute _root to just start navigating from the very
top-level type:
TODO
seq:
- id: header
type: main_header
types:
main_header:
seq:
- id: magic
contents: MY-SUPER-FORMAT
- id: body_len
type: u4
- id: subbody_len
type: u44.10. Conditionals
Some protocols and file formats have optional fields, which only exist
in some conditions. For example, one can have some byte first that
designates if some other field exists (1) or not (0). In Kaitai Struct, you can do that
using the if key:
seq:
- id: has_crc32
type: u1
- id: crc32
type: u4
if: has_crc32 != 0In this example, we again use expression language to specify a boolean
expression in the if key. If that expression is true, the field is parsed and
we’ll get a result. If that expression is false, the field will be skipped
and we’ll get a null (or its closest equivalent in our target
programming language) if we try to get it.
At this point, you might wonder how that plays together with enums. After you mark some integer as "enum", it’s no longer just an integer, so you can’t compare it directly with the number. Instead you’re expected to compare it to other enum values:
seq:
- id: my_animal
type: u1
enum: animal
- id: dog_tag
type: u4
# Comparing to enum literal
if: my_animal == animal::dog
enums:
animal:
1: cat
2: dogThere are other enum operations available, which we’ll cover in the expression language guide later.
4.11. Repetitions
Most real-life file formats do not contain only one copy of some element, but might contain several copies, i.e. they repeat the same pattern over and over. Repetition might be:
-
element repeated up to the very end of the stream
-
element repeated a pre-defined number of times
-
element repeated while some condition is not satisfied (or until some condition becomes true)
Kaitai Struct supports all these types of repetitions. In all cases, it will create a resizable array (or nearest equivalent available in the target language) and populate it with elements.
4.11.1. Repeat until end of stream
This is the simplest kind of repetition, done by specifying
repeat: eos. For example:
seq:
- id: numbers
type: u4
repeat: eosThis yields an array of unsigned integers, each 4 bytes long, which spans till the end of the stream. Note that if we’ve got a number of bytes left in the stream that’s not divisible by 4 (for example, 7), we’ll end up reading as much as possible, and then the parsing procedure will throw an end-of-stream exception.
Of course, you can do this with any type, including user-defined types (subtypes):
seq:
- id: filenames
type: filename
repeat: eos
types:
filename:
seq:
- id: name
type: str
size: 8
encoding: ASCII
- id: ext
type: str
size: 3
encoding: ASCIIThis one defines an array of records of type filename. Each individual
filename consists of 8-byte name and 3-byte ext strings in ASCII
encoding.
4.11.2. Repeat for a number of times
One can repeat an element a certain number of times. For that, we’ll need an expression that will give us the number of iterations (which would be exactly the number of items in resulting array). It could be a simple constant to read exactly 12 numbers:
seq:
- id: numbers
type: u4
repeat: expr
repeat-expr: 12Or we might reference some attribute here to have an array with the length specified inside the format:
seq:
- id: num_floats
type: u4
- id: floats
type: f8
repeat: expr
repeat-expr: num_floatsOr, using expression language, we can even do some more complex math on it:
seq:
- id: width
type: u4
- id: height
type: u4
- id: matrix
type: f8
repeat: expr
repeat-expr: width * heightThis one specifies the width and height of the matrix first, then parses
as many matrix elements as needed to fill a width × height matrix
(although note that it won’t be a true 2D matrix: it would still be just
a regular 1D array, and you’ll need to convert (x, y) coordinates to
indices in that 1D array manually).
4.11.3. Repeat until condition is met
Some formats don’t specify the number of elements in array, but instead
just use some sort of special element as a terminator that signifies end
of data. Kaitai Struct can do that as well using repeat-until syntax, for
example:
seq:
- id: numbers
type: s4
repeat: until
repeat-until: _ == -1This one reads 4-byte signed integer numbers until encountering -1. On
encountering -1, the loop will stop and further sequence elements (if
any) will be processed. Note that -1 would still be added to array.
Underscore (_) is used as a special variable name that refers to the
element that we’ve just parsed. When parsing an array of user types, it
is possible to write a repeat-until expression that would reference some
attribute inside that user type:
seq:
- id: records
type: buffer_with_len
repeat: until
repeat-until: _.len == 0
types:
buffer_with_len:
seq:
- id: len
type: u1
- id: value
size: len4.12. Typical TLV implementation (switching types on an expression)
"TLV" stands for "type-length-value", and it’s a very common staple in
many formats. The basic idea is that we use a modular and
reverse-compatible format. On the top level, it’s very simple: we know
that the whole format is just an array of records (repeat: eos or
repeat: expr). Each record starts the same: there is some marker that
specifies the type of the record and an integer that specifies the record’s
length. After that, the record’s body follows, and the body format
depends on the type marker. One can easily specify that basic record
outline in Kaitai Struct like that:
seq:
- id: rec_type
type: u1
- id: len
type: u4
- id: body
size: lenHowever, how do we specify the format for body that depends on
rec_type? One of the approaches is using conditionals, as we’ve seen
before:
seq:
- id: rec_type
type: u1
- id: len
type: u4
- id: body_1
type: rec_type_1
size: len
if: rec_type == 1
- id: body_2
type: rec_type_2
size: len
if: rec_type == 2
# ...
- id: body_unidentified
size: len
if: rec_type != 1 and rec_type != 2 # and ...However, it’s easy to see why it’s not a very good solution:
-
We end up writing lots of repetitive lines
-
We create lots of
body_*attributes in a type, while in reality only onebodywould exist — everything else would fail theifcomparison and thus would be null -
If we want to catch up the "else" branch, i.e. match everything not matched with our
ifs, we have to write an inverse of sum ofifs manually. For anything more than 1 or 2 types it quickly becomes a mess.
That is why Kaitai Struct offers an alternative solution. We can use a switch type operation:
seq:
- id: rec_type
type: u1
- id: len
type: u4
- id: body
size: len
type:
switch-on: rec_type
cases:
1: rec_type_1
2: rec_type_2This is much more concise and easier to maintain, isn’t it? And note
that size is specified on the attribute level, thus it applies to all
possible type values, setting us a good hard limit. What’s even better —
even if you’re missing the match, as long as you have size specified,
you would still parse body of a given size, but instead of
interpreting it with some user type, it will be treated as having no
type, thus yielding a raw byte array. This is super useful, as it
allows you to work on TLV-like formats step-by-step, starting by
supporting only 1 or 2 types of records, and gradually adding more and
more types.
|
Caution
|
One needs to make sure that the type used in Here, |
You can use "_" for the default (else) case which will match every other value which was not listed explicitly.
type:
switch-on: rec_type
cases:
1: rec_type_1
2: rec_type_2
_: rec_type_unknownSwitching types can be a very useful technique. For more advanced usage examples, see Advanced switching.
4.13. Instances: data beyond the sequence
So far we’ve done all the data specifications in seq — thus they’ll
get parsed immediately from the beginning of the stream, one-by-one, in
strict sequence. But what if the data you want is located at some other
position in the file, or comes not in sequence?
"Instances" are Kaitai Struct’s answer for that. They’re specified
in a key instances on the same level as seq. Consider this example:
meta:
id: big_file
endian: le
instances:
some_integer:
pos: 0x400000
type: u4
a_string:
pos: 0x500fff
type: str
size: 0x11
encoding: ASCIIInside instances we need to create a map: keys in that map are
attribute names, and values specify attribute in the very same manner as
we would have done it in seq, but there is one important additional
feature: using pos: … one can specify a position to start parsing
that attribute from (in bytes from the beginning of the stream). Just as
in size, one may use expression language and reference other
attributes in pos. This is used very often to allow accessing a file
body inside a container file when we have some file index data: file
position in container and length:
seq:
- id: file_name
type: str
size: 8 + 3
encoding: ASCII
- id: file_offset
type: u4
- id: file_size
type: u4
instances:
body:
pos: file_offset
size: file_sizeAnother very important difference between the seq attribute and the
instances attribute is that instances are lazy by default. What does
that mean? Unless someone would call that body getter method
programmatically, no actual parsing of body would be done. This is
super useful for parsing larger files, such as images of filesystems. It
is impractical for a filesystem user to load all the filesystem data
into memory at once: one usually finds a file by its name (traversing a
file index somehow), and then can access file’s body right away. If
that’s the first time this file is being accessed, body will be loaded
(and parsed) into RAM. Second and all subsequent times will just return
a cached copy from the RAM, avoiding any unnecessary re-loading /
re-parsing, thus conserving both RAM and CPU time.
Note that from the programming point of view (from the target
programming languages and from internal Kaitai Struct’s expression
language), seq attributes and instances are exactly the same.
4.14. Value instances
Sometimes, it is useful to transform the data (using expression
language) and store it as a named value. There’s another sort of
instances for that — value instances. They’re very
simple to use, there’s only one key in it — value — that specifies an
expression to calculate:
seq:
- id: length_in_feet
type: f8
instances:
length_in_m:
value: length_in_feet * 0.3048Value instances do no actual parsing, and thus do not require a pos
key or a type key (the type will be derived automatically). If you need
to enforce the type of the expression, see typecasting.
4.15. Bit-sized integers
Quite a few protocols and file formats, especially those which aim to conserve space, pack multiple integers into one byte, using integer sizes less than 8 bits. For example, an IPv4 packet starts with a byte that packs both a version number and header length:
76543210 vvvvllll │ │ │ └─ header length └───── version
It’s possible to unpack bit-packed integers using old-school methods with bitwise operations in value instances:
seq:
- id: packed_1
type: u1
instances:
version:
value: (packed_1 & 0b11110000) >> 4
len_header:
value: packed_1 & 0b00001111However, Kaitai Struct offers a better way to do it — using bit-sized integers.
4.15.1. Big-endian order
|
Important
|
Feature available since v0.6. |
Here’s how the above IPv4 example can be parsed with Kaitai Struct:
meta:
bit-endian: be
seq:
- id: version
type: b4
- id: len_header
type: b4Using the meta/bit-endian key, we specify big-endian bit field order
(see Specifying bit endianness for more info). In this mode, Kaitai Struct starts parsing bit
fields from the most significant bit (MSB, 7) to the least significant bit
(LSB, 0). In this case, "version" comes first and "len_header" second.
The bit layout for the above example looks like this:
d[0]
7 6 5 4 3 2 1 0
v3 v2 v1 v0 h3 h2 h1 h0
───────┬────── ───────┬──────
version len_header
d[0] is the first byte of the stream, and the numbers 7-0 on the line
below indicate the invididual bits of this byte (listed from MSB 7 to LSB 0).
The value of version can be retrieved as 0b{v3}{v2}{v1}{v0}
(0b… is the binary integer literal as present in many programming
languages, and {v3} is the value 0 or 1 of the corresponding bit),
and the len_header value can be retrieved as 0b{h3}{h2}{h1}{h0}.
Using type: bX (where X is a number of bits to read) is very
versatile and can be used to read byte-unaligned data. A more complex
example of packing, where value spans two bytes:
d[0] d[1]
7 6 5 4 3 2 1 0 7 6 5 4 3 2 1 0
a4 a3 a2 a1 a0 b8 b7 b6 b5 b4 b3 b2 b1 b0 c1 c0
─────────┬──────── ─────────────────┬────────────────── ───┬──
a b c
│ ───────────────────────────> │ │ ───────────────────────────> │
parsing direction ╷ ↑
└┄┄┘
meta:
bit-endian: be
seq:
- id: a
type: b5
- id: b
type: b9
# 3 bits (b{8-6}) + 6 bits (b{5-0})
- id: c
type: b2|
Note
|
Why is this order of bit field members called "big-endian"? Because
the parsing results are equivalent to first reading a packed
integer in big-endian byte order and then extracting the values
using bitwise operators ( Using the same logic, little-endian bit integers correspond to unpacking a little-endian integer instead. See Little-endian order for more info. |
Or it can be used to parse completely unaligned bit streams with repetitions. In this example, we parse an arbitrary number of 3-bit values:
d[0] d[1] d[2] d[3]
76543210 76543210 76543210 76543210
nnnnnnnn 00011122 23334445 55666777 ...
________ ‾‾‾___‾‾‾‾___‾‾‾____
╷ │ ╷ │ ╷ │ ╷
num_threes ────┘ │ │ │ │ │ │
threes[0] ──────────┘ │ │ │ │ │
threes[1] ─────────────┘ │ │ │ │
threes[2] ────────────────┘ │ │ │
threes[3] ────────────────────┘ │ │
threes[4] ───────────────────────┘ │
threes[5] ───────────────────────────┘
...
meta:
bit-endian: be
seq:
- id: num_threes
type: u1
- id: threes
type: b3
repeat: expr
repeat-expr: num_thress|
Important
|
By default, if you mix "normal" byte-sized integers (i.e. two bytes will get parsed like this: 76543210 76543210
ffffff bbbbbbbb
──┬─── ───┬────
| |
foo ──┘ |
bar ────────────┘
i.e. the two least significant bits of the first byte would be lost and not parsed due to alignment. |
4.15.2. Little-endian order
|
Important
|
Feature available since v0.9. |
Most formats using little-endian byte order with packed multi-byte bit fields (e.g. android_img, rar or swf) assume that such bit fields are unpacked manually using bitwise operators from a little-endian integer parsed in advance containing the whole bit field. The bit layout of the field is designed accordingly.
For example, consider the following bit field:
seq:
- id: packed
type: u2le
instances:
a:
value: (packed & 0b11111000_00000000) >> (3 + 8)
b:
value: (packed & 0b00000111_11111100) >> 2
c:
value: packed & 0b00000000_00000011The expressions for extracting the values look exactly the same as
for the big-endian order, but the actual bit layout
will be different, because here the packed integer is read
in little-endian (LE) byte order.
Given that d is a 2-byte array needed to parse an unsigned 2-byte
integer, the numeric value of a BE integer is
0x{d[0]}{d[1]} (0x… is the hexadecimal integer literal
and {d[0]} is the hex value of byte d[0] as seen in hex dumps,
e.g. 02 or 7f), whereas the value of a LE integer
would be 0x{d[1]}{d[0]}.
It follows that if we read a BE integer from a new byte array
[d[1], d[0]] (i.e. d reversed), we’ll get the same result
as when reading a LE integer from the original d array.
Because we’ve already explained how bit-integers work in
big-endian order, let’s repeat this method for the
above bitfield on the byte array d reversed (d[1] d[0]) and then
swap the bytes back to the original order of d (d[0] d[1]):
d[1] d[0]
7 6 5 4 3 2 1 0 7 6 5 4 3 2 1 0
a4 a3 a2 a1 a0 b8 b7 b6 b5 b4 b3 b2 b1 b0 c1 c0
──────────────┬─────────────── ───────────────┬──────────────
└──────────────╷ ╷───────────────┘
╲ ╱
╳
╱ ╲
┌──────────────╵ ╵──────────────┐
d[0] d[1]
7 6 5 4 3 2 1 0 7 6 5 4 3 2 1 0
b5 b4 b3 b2 b1 b0 c1 c0 a4 a3 a2 a1 a0 b8 b7 b6
──────────┬─────────── ──┬─── ─────────┬──────── ────┬─────
b c a b
│ <──────────────────────────── │ │ <──────────────────────────── │
╷ parsing direction ↑
└┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈>┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┘
As you can guess from the bit layout, you can’t use big-endian
bit integers here without splitting the b value into 2 separate
members.
This is because each byte in a big-endian bit field is gradually "filled"
with members from the most significant bit (7) to the least significant (0),
and if the current byte is filled up to LSB, the parsing continues on
MSB of next byte. It follows that b really can’t be represented
with a single attribute using this order, because c and a are standing
in the way.
Little-endian bit fields use the reversed parsing direction: bytes are filled from LSB (0) to MSB (7), and after filling the byte up to MSB, values overflow to the next byte’s LSB.
For example, the above bit layout can be conveniently represented using little-endian bit integers:
meta:
bit-endian: le
seq:
- id: c
type: b2
- id: b
type: b9
# 6 bits (b{5-0}) + 3 bits (b{8-6})
- id: a
type: b5As you can see in the KSY snippet, the bit field members in seq
are listed from the least significant value to the most significant.
If we look at the bit masks of bit field members (which can be
directly used for ANDing & with the 2-byte little-endian unsigned
value), they would be sorted in ascending order (starting with
the least significant value):
c 0b00000000_00000011 b 0b00000111_11111100 a 0b11111000_00000000
This may seem strange at first, but it’s actually natural from the perspective of how little-endian bit fields work, and how they physically store their members.
Thanks to this order, Kaitai Struct doesn’t need to know the byte
size of the whole bitfield in advance (so that its members could
be rearranged at compile-time to match their physical location),
and it can normally parse the attributes on the run.
It follows that little-endian bit-sized integers can be normally
combined with if conditions and repetitions like any other Kaitai Struct type.
4.15.3. Specifying bit endianness
The key meta/bit-endian specifies the default parsing direction
(bit endianness) of bit-sized integers. It can only have the
literal value le or be (run-time switching
is not supported).
|
Important
|
Support for However, if you don’t really need to support pre-0.9 KSC
versions, it’s recommended to state |
Like meta/endian, meta/bit-endian also applies to bX attributes
in the current type and all subtypes, but it can be overridden
using the le/be suffix (bXle/bXbe) for the individual bit
integers. For example:
meta:
bit-endian: le
seq:
- id: foo
type: b2 # little-endian
types:
my_subtype:
seq:
- id: bar
type: b8 # also little-endian
- id: baz
type: b16be # big-endian|
Important
|
Big-endian and little-endian bit integers can follow only on a byte boundary. They can’t share the same byte. Joining them on an unaligned bit position is undefined behavior, and future versions of KSC will throw a compile-time error if they detect such a situation. For example, this is illegal: |
4.16. Documenting your spec
We introduced the doc key early in this user guide as
a simple way to add docstrings to the attributes. However, it’s not
only attributes that can be documented. The same doc key can be used
in several different contexts:
doc: |
Documentation for type. Works for top-level types too, in case you
were wondering.
seq:
- id: attr_1
type: u1
doc: Documentation for sequence attribute.
instances:
attr_2:
pos: 0x1234
type: u1
doc: Documentation for parse instance attribute.
attr_3:
value: attr_2 + 1
doc: Documentation for value instance attribute.
types:
some_type:
doc: Documentation for type as well. Works for inner types too.
params:
- id: param_1
type: u1
doc: |
Documentation for a parameter. Parameters are a relatively
advanced topic, see below for the explanations.4.16.1. doc-ref
The doc key has a "sister" key doc-ref, which can be used to specify
references to original documentation. This is very useful to keep
track of what corresponds to what when transcribing an existing
specification. Everywhere where you can use doc, you can use
doc-ref as well. Depending on the target language, this key would be
rendered as something akin to a "see also" extra paragraph after the
main docstring. For example:
Kaitai Struct
|
Java
|
Inside doc-ref, one can specify:
-
Just a user-readable string. Most widely used to reference offline documentation. User would need to find relevant portion of documentation manually.
doc-ref: ISO-9876 spec, section 1.2.3 -
Just a link. Used when existing documentation has a non-ambiguous, well defined URL that everyone can refer to, and there’s nothing much to add to it.
doc-ref: https://www.youtube.com/watch?v=dQw4w9WgXcQ -
Link + description. Used when adding some extra text information is beneficial: for example, when a URL is not enough and needs some comments on how to find relevant info inside the document, or the document is also accessible through some other means and it’s useful to specify both URL and section numbering for those who won’t be using the URL. In this case,
doc-refis composed of a URL, then a space, then a description.doc-ref: https://tools.ietf.org/html/rfc2795#section-6.1 RFC2795, 6.1 "SIMIAN Client Requests"
4.16.2. -orig-id
When transcribing spec based on some existing implementation, most
likely you won’t be able to keep exact same spelling of all
identifiers. Kaitai Struct imposes pretty draconian rules on what can
be used as id, and there is a good reason for it: different target
languages have different ideas of what constitutes a good identifier,
so Kaitai Struct had to choose some "middle ground" that yields decent
results when converted to all supported languages' standards.
However, in many cases, it might be useful to keep references to how
things were named in original implementation. For that, one can
customarily use -orig-id key:
seq:
- id: len_str_buf
-orig-id: StringBufferSize
type: u4
- id: str_buf
-orig-id: StringDataInputBuffer
size: len_str_buf|
Tip
|
The Kaitai Struct compiler will just ignore any key that starts with
|
4.16.3. Verbose enums
|
Important
|
Feature available since v0.8. |
If you want to add some documentation for enums, this is possible using verbose enums declaration:
enums:
ip_protocol:
1:
id: icmp
doc: Internet Control Message Protocol
doc-ref: https://www.ietf.org/rfc/rfc792
6:
id: tcp
doc: Transmission Control Protocol
doc-ref: https://www.ietf.org/rfc/rfc793
17:
id: udp
doc: User Datagram Protocol
doc-ref: https://www.ietf.org/rfc/rfc768In this format, instead of specifying just the identifier for every
numeric value, you specify a YAML map, which has an id key for
the identifier, and allows other regular keys (like doc and doc-ref)
to specify documentation.
4.17. Meta section
The meta key is used to define a section which stores meta-information
about a given type, i.e. various complimentary stuff, such as titles,
descriptions, pointers to external linked resources, etc:
-
id -
title -
application -
file-extension -
xref— used to specify cross-references -
license -
tags -
ks-version -
ks-debug -
ks-opaque-types -
imports -
encoding -
endian
|
Tip
|
While it’s technically possible to specify meta keys in
arbitary order (as in any other YAML map), please use the order
recommended in the KSY style guide when
authoring .ksy specs for public use to improve readability.
|
4.17.1. Cross-references
meta/xref can be used to provide arbitrary cross-references for a
particular type in other collections, such as references / IDs in
format databases, wikis, encyclopedias, archives, formal standards,
etc. Syntactically, it’s just a place where you can store arbitrary
key-value pairs, e.g.:
meta:
xref:
forensicswiki: portable_network_graphics_(png)
iso: '15948:2004'
justsolve: PNG
loc: fdd000153
mime: image/png
pronom:
- fmt/13
- fmt/12
- fmt/11
rfc: 2083
wikidata: Q178051There are several "well-known" keys used by convention by many spec authors to provide good cross references of their formats:
-
forensicswikispecifies an article name at Forensics Wiki, which is a CC-BY-SA-licensed wiki with information on digital forensics, file formats and tools. A full link could be generated ashttps://forensics.wiki/+ this value +/.For consistency, insert parentheses in this value literally (without using percent-encoding) - e.g. use
extended_file_system_(ext)instead ofextended_file_system_%28ext%29. -
isospecifies an ISO/IEC standard number, a reference to a standard accepted and published by ISO (International Organization for Standardization). Typically these standards are not available for free (i.e. one has to pay to get a copy of a standard from ISO), and it’s non-trivial to link to the ISO standards catalogue. However, ISO standards typically have clear designations like "ISO/IEC 15948:2004", so the value should cite everything except for "ISO/IEC", e.g.15948:2004. -
justsolvespecifies an article name at "Just Solve the File Format Problem" wiki, a wiki that collects information on many file formats. A full link could be generated ashttp://fileformats.archiveteam.org/wiki/+ this value. -
locspecifies an identifier in the Digital Formats database of the US Library of Congress, a major effort to enumerate and document many file formats for digital preservation purposes. The value typically looks likefddXXXXXX, whereXXXXXXis a 6-digit identifier. -
mimespecifies a MIME (Multipurpose Internet Mail Extensions) type, AKA "media type" designation, a string typically used in various Internet protocols to specify format of binary payload. As of 2019, there is a central registry of media types managed by IANA. The value must specify the full MIME type (both parts), e.g.image/png. -
pronomspecifies a format identifier in the PRONOM Technical Registry of the UK National Archives, which is a massive file formats database that catalogues many file formats for digital preservation purposes. The value typically looks likefmt/xxx, wherexxxis a number assigned at PRONOM (this idenitifer is called a "PUID", AKA "PRONOM Unique Identifier" in PRONOM itself). If many different PRONOM formats correspond to a particular spec, specify them as a YAML array (see example above). -
rfcspecifies a reference to RFC, "Request for Comments" documents maintained by ISOC (Internet Society). Despite the confusing name, RFCs are typically treated as global, Internet-wide standards, and, for example, many networking / interoperability protocols are specified in RFCs. The value should be just the raw RFC number, without any prefixes, e.g.1234. -
wikidataspecifies an item name at Wikidata, a global knowledge base. All Wikimedia projects (such as language-specific Wikipedias, Wiktionaries, etc) use Wikidata at least for connecting various translations of encyclopedic articles on a particular subject, so keeping just a link to Wikidata is typically enough to. The value typically follows aQxxxpattern, wherexxxis a number generated by Wikidata, e.g.Q535473.
5. Streams and substreams
Imagine that we’re dealing with a structure of known size. For the sake of simplicity, let’s say that it’s fixed to exactly 20 bytes (but all the following is also true if the size is defined by some arbitrarily complex expression):
types:
person:
seq:
- id: code
type: u4
- id: name
type: str
size: 16When we’re invoking user-defined types, we can do either:
seq:
- id: joe
type: personor:
seq:
- id: joe
type: person
size: 20Note the subtle difference: we’ve skipped the size in the first example
and added it in the second one. From the end-user’s perspective, nothing
has changed. You can still access Joe’s code and name equally well in
both cases:
r.joe().code() // works
r.joe().name() // worksHowever, what gets changed under the hood? It turns out that
specifying size actually brings some new features: if you modify the
person type to be less than 20 bytes long, it still reserves exactly
20 bytes for joe:
seq:
- id: joe # reads from position 0
type: person
size: 20
- id: foo
type: u4 # reads from position 20
types:
person: # although this type is 14 bytes long now
seq:
- id: code
type: u4
- id: name
type: str
size: 10In this example, the extra 6 bytes would just be skipped. Alternatively,
if you make person to be more than 20 bytes long, it will
trigger an end-of-stream exception:
seq:
- id: joe
type: person
size: 20
- id: foo
type: u4
types:
person: # 100 bytes is longer than 20 bytes declared in `size`
seq:
- id: code
type: u4
- id: name # will trigger an exception here
type: str
size: 96How does it work? Let’s take a look under the hood.
Sizeless user type invocation generates the following parsing code:
this.joe = new Person(this._io, this, _root);However, when we declare the size, things get a little bit more
complicated:
this._raw_joe = this._io.readBytes(20);
KaitaiStream _io__raw_joe = new KaitaiStream(_raw_joe);
this.joe = new Person(_io__raw_joe, this, _root);Every class that Kaitai Struct generates carries a concept of a "stream", usually
available as an _io member. This is the default stream it reads from
and writes to. This stream works just as you might expect from a
regular IO stream implementation in a typical language: it
encapsulates reading from files and memory, stores a pointer to its
current position, and allows reading/writing of various primitives.
Declaring a new user-defined type in the middle of the seq attributes
generates a new object (usually via a constructor call), and this object,
in turn, needs its own IO stream. So, what are our options here?
-
In the "sizeless" case, we just pass the current
_ioalong to the new object. This "reuses" the existing stream with all its properties: current pointer position, size, available bytes, etc. -
In the "sized" case, we know the size a priori and want the object we created to be limited within that size. So, instead of passing an existing stream, we create a new substream that will be shorter and will contain the exact number of bytes requested.
Implementations vary from language to language, but, for example, in Java, the following is done:
// First, we read as many bytes as needed from our current IO stream.
// Note that if we don't even have 20 bytes right now, this will throw
// an EOS exception on this line, and the user type won't even be invoked.
this._raw_joe = this._io.readBytes(20);
// Second, we wrap our bytes into a new stream, a substream
KaitaiStream _io__raw_joe = new KaitaiStream(_raw_joe);
// Finally, we pass our substream to the Person class instead of
this.joe = new Person(_io__raw_joe, this, _root);After that, parsing of a person type will be totally bound to the limits
of that particular substream. Nothing in the Person class
can do a thing to the original stream — it just doesn’t have access to
that object.
Let’s check out a few use cases that demonstrate how powerful this practice can be.
5.1. Limiting total size of structure
Quite often binary formats use the following technique:
-
First comes some integer that declares the total size of the structure (or the structure’s body, i.e. everything minus this header).
-
Then comes the structure’s body, which is expected to have exactly the declared number of bytes.
Consider this example:
seq:
- id: body_len
type: u4
# The following must be exactly `body_len` bytes long
- id: uuid
size: 16
- id: name
type: str
size: 24
- id: price
type: u4
# This "comment" entry must fill up all remaining bytes up to the
# total of `body_len`.
- id: comment
size: ???Of course, one can derive this manually:
-
body_len = sizeof(uuid) + sizeof(name) + sizeof(price) + sizeof(comment)
-
body_len = 16 + 24 + 4 + sizeof(comment)
-
sizeof(comment) = body_len - (16 + 24 + 4)
-
sizeof(comment) = body_len - 44
Thus:
- id: comment
size: body_len - 44But this is very inconvenient and potentially error prone. What will happen if at some time in future the record contents are updated and we forget to update this formula?
It turns out that substreams offer a much cleaner solution here. Let’s
separate our "header" and "body" into two distinct user types, and
then we can just specify size on this body:
seq:
- id: body_len
type: u4
- id: body
type: record_body
size: body_len
# ^^ This is where substream magic kicks in
types:
record_body:
seq:
- id: uuid
size: 16
- id: name
type: str
size: 24
- id: price
type: u4
- id: comment
size-eos: trueFor comment, we just made its size to be up until the end of
stream. Given that we’ve limited it to the substream in the first
place, this is exactly what we wanted.
5.2. Repeating until total size reaches limit
The same technique might be useful for repetitions as well. If you have an array of same-type entries, and a format declares the total size of all entries combined, again, you can try to do this:
seq:
- id: total_len
type: u4
- id: entries
type: entry
repeat: expr
repeat-expr: ???And do some derivations to calculate number of entries, i.e. "total_len / sizeof(entry)". But, again, this is bad because:
-
You need to keep remembering to update this "sizeof" value when the entry size updates.
-
If the entry size if not fixed, you’re totally out of luck here.
Solving it using substreams is much more elegant. You just create a
substream limited to total_len bytes, and then use repeat: eos to
repeat until the end of that stream.
|
Caution
|
However, note that one’s naïve approach might not work:
So this is wrong ( For more information, see Keys relating to the whole array and to each element in repeated attributes. The proper solution is to add an extra layer of types: |
5.3. Relative positioning
Another useful feature that’s possible with substreams is the fact that
while you’re in a substream, the pos key works in the context of that
substream as well. That means it addresses data relative to the start of that
substream:
seq:
- id: some_header
size: 20
- id: body
type: block
size: 80
types:
block:
seq:
- id: foo
type: u4
instances:
some_bytes_in_the_middle:
pos: 30
size: 16In this example, body allocates a substream spanning from 20th byte
(inclusive) till 100th byte (exclusive). Then, in that stream:
-
foowould be parsed right from the beginning of that substream, thus taking up bytes[20..24) -
some_bytes_in_the_middlewould start parsing 16 bytes from the 30th byte of that substream, thus parsing bytes[20 + 30 .. 20 + 46)=[50..66)in the main stream.
This comes super handy if your format’s internal structures somehow specify offsets relative to some other structures of the format. For example, a typical filesystem/database often uses a concept of blocks, and offsets that address stuff inside the current block. Note how KSY with substreams is easier to read, more concise and less error-prone:
Bad (w/o substream)
|
Good (w/substream)
|
The more levels of structure offset nesting there are, the more
complicated these pos expressions would get without substreams.
5.4. Absolute positioning
If you ever need to "escape" the limitations of a substream by
wishing to use a pos key of a parse instance to address something absolutely
(i.e. in the main stream), it’s easy to do so by adding an io key to
choose the root’s stream:
seq:
- id: some_header
size: 20
- id: files
size: 80
type: file_entry
repeat: eos
types:
file_entry:
seq:
- id: file_name
type: strz
- id: ofs_body
type: u4
- id: len_body
type: u4
instances:
body:
io: _root._io
pos: ofs_body
size: len_bodyThat’s the typical situation encountered in many file container
formats. Here we have a list of files, and each of its entries has
been limited to exactly 80 bytes. Inside each 80-byte chunk, there’s a
file_name, and, more importantly, a pointer to the absolute location of
the file’s body inside the stream. The body instance allows us to get that
file’s body contents quickly and easily. Note that if there was no
io: _root._io key there, that body would have been parsed inside a
80-byte substream (and most likely that would result in an exception
trying to read outside of the 80 byte limit), and that’s not what we want
here.
5.5. Choosing a substream
The technique above is not limited to just the root object’s stream. You can address any other object’s stream as well, for example:
seq:
- id: global_header
size: 1024
- id: block_one
type: big_container
size: 4096
- id: block_two
type: smaller_container
size: 1024
types:
big_container:
seq:
- id: some_header
size: 8
# the rest of the data in this container would be referenced
# from other blocks
smaller_container:
seq:
- id: ofs_in_big
type: u4
- id: len_in_big
type: u4
instances:
something_in_big:
io: _root.block_one._io
pos: ofs_in_big
size: len_in_big5.6. Processing: dealing with compressed, obfuscated and encrypted data
Some formats obscure the data fully or partially with techniques like compression, obfuscation or encryption. In these cases, incoming data should be pre-processed before actual parsing takes place, or we’ll just end up with garbage getting parsed. All such pre-processing algorithms have one thing in common: they’re done by some function that takes a stream of bytes and returns another stream of bytes (note that the number of incoming and resulting bytes might be different, especially in the case of decompression). While it might be possible to do such transformation in a declarative manner, it is usually impractical to do so.
Kaitai Struct allows you to plug-in some predefined "processing" algorithms to do decompression, de-obfuscation and decryption to get a clear stream, ready to be parsed. Consider parsing a file, in which the main body is obfuscated by applying XOR with 0xaa for every byte:
seq:
- id: body_len
type: u4
- id: body
size: body_len
process: xor(0xaa)
type: some_body_type # defined normally laterNote that:
-
Applying
process: …is available only to raw byte arrays or user types. -
One might use expression language inside
xor(…), thus referencing the XOR obfuscation key read into some other field previously.
6. Expression language
Expression language is a powerful internal tool inside Kaitai Struct. In a nutshell, it is a simple object-oriented, statically-typed language that gets translated/compiled (AKA "transpiled") into any supported target programming language.
The language is designed to follow the principle of least surprise, so it borrows tons of elements from other popular languages, like C, Java, C#, Ruby, Python, JavaScript, Scala, etc.
6.1. Basic data types
Expression language operates on the following primitive data types:
| Type | Attribute specs | Literals |
|---|---|---|
Integers |
|
|
Floating point numbers |
|
|
Booleans |
|
|
Byte arrays |
|
|
Strings |
|
|
Enums |
( |
|
Streams |
N/A |
N/A |
Integers come from uX, sX, bX type specifications in sequence
or instance attributes (i.e. u1, u4le, s8, b3, etc), or can be
specified literally. One can use:
-
decimal form (e.g.
123) -
hexadecimal form using
0xprefix (e.g.0xcafe— both upper case and lower case letters are legal, i.e.0XcAfEor0xCAfewill do as well) -
binary form using
0bprefix (e.g.0b00111011) -
octal form using
0oprefix (e.g.0o755)
It’s possible to use _ as a visual separator in literals — it will
be completely ignored by the parser. This could be useful, for example,
to:
-
visually separate thousands in decimal numbers:
123_456_789 -
show individual bytes/words in hex:
0x1234_5678_abcd -
show nibbles/bytes in binary:
0b1101_0111
Floating point numbers also follow the normal notation used in the vast
majority of languages: 123.456 will work, as well as exponential
notation: 123.456e-55. Use 123.0 to enforce floating point type to
an otherwise integer literal.
Booleans can be specified as literal true and false values as in
most languages, but also can be derived by using type: b1. This
method parses a single bit from a stream and represents it as a
boolean value: 0 becomes false, 1 becomes true. This is very useful to
parse flag bitfields, as you can omit flag_foo != 0 syntax and just
use something more concise, such as is_foo.
Byte arrays are defined in the attribute syntax when you don’t
specify anything as type. The size of a byte array is thus determined
using size, size-eos or terminator, one of which is mandatory in
this case. Byte array literals use typical array syntax like the one
used in Python, Ruby and JavaScript: i.e. [1, 2, 3]. There is a
little catch here: the same syntax is used for "true" arrays of
objects (see below), so if you try to do stuff like [1, 1000, 5]
(1000 obviously won’t fit in a byte), you won’t get a byte array,
you’ll get an array of integers instead.
Strings normally come from using type: str (or type: strz, which
is a shortcut that implicitly adds terminator: 0).
Literal strings can be specified using double quotes or single
quotes. The meaning of single and double quotes is similar to those of
Ruby, PHP and Shell script:
-
Single quoted strings are interpreted literally, i.e. backslash
\, double quotes"and other possible special symbols carry no special meaning, they would be just considered a part of the string. Everything between single quotes is interpreted literally, i.e. there is no way one can include a single quote inside a single quoted string. -
Double quoted strings support escape sequences and thus allow you to specify any characters. The supported escape sequences are as follows:
| Escape seq | Code (dec) | Code (hex) | Meaning |
|---|---|---|---|
|
7 |
0x7 |
bell |
|
8 |
0x8 |
backspace |
|
9 |
0x9 |
horizontal tab |
|
10 |
0xa |
newline |
|
11 |
0xb |
vertical tab |
|
12 |
0xc |
form feed |
|
13 |
0xd |
carriage return |
|
27 |
0x1b |
escape |
|
34 |
0x22 |
double quote |
|
39 |
0x27 |
single quote (technically not required, but supported) |
|
92 |
0x5c |
backslash |
|
ASCII character with octal code 123; one can specify 1..3 octal digits |
||
|
Unicode character with code U+12BF; one must specify exactly 4 hex digits |
|
Note
|
One of the most widely used control characters, ASCII zero
character (code 0) can be specified as \0 — exactly as it works in
most languages.
|
|
Caution
|
Octal notation is prone to errors: due to its flexible
length, it can swallow decimal digits that appear after the code as
part of octal specification. For example, a\0b is three characters:
a, ASCII zero, b. However, 1\02 is interpreted as two
characters: 1 and ASCII code 2, as \02 is interpreted as one octal
escape sequence.
|
TODO: Enums
Streams are internal objects that track the byte stream that we
parse and the state of parsing (i.e. where the pointer is). There is no
way to declare a stream-type attribute directly by parsing
instructions or specify it as a literal. The typical way to get stream
objects is to query the _io attribute from a user-defined object: that
will give us a stream associated with this particular object.
6.2. Composite data types
There are two composite data types in the expression language (i.e. data types which include other types as components).
6.2.1. User-defined types
User-defined types are the types one defines using .ksy syntax —
i.e. the top-level structure and all substructures defined in the types key.
Normally, they are translated into classes (or their closest available equivalent — i.e. a storage structure with members + access members) in the target language.
6.2.2. Arrays
Array types are just what one might expect from an all-purpose, generic
array type. Arrays come from either using the repetition syntax
(repeat: …) in an attribute specification, or by specifying a literal
array. In any case, all Kaitai Struct arrays have an underlying data type that they
store, i.e. one can’t put strings and integers into the same
array. One can do arrays based on any primitive data type or composite
data type.
|
Note
|
"True" array types (described in this section) and "byte arrays" share the same literal syntax and lots of method APIs, but they are actually very different types. This is done on purpose, because many target languages use very different types for byte arrays and arrays of objects for performance reasons. |
One can use array literals syntax to declare an array (very similar to the syntax used in JavaScript, Python and Ruby). Type will be derived automatically based on the types of values inside brackets, for example:
-
[123, 456, -789]— array of integers -
[123.456, 1.234e+78]— array of floats -
["foo", "bar"]— array of strings -
[true, true, false]— array of booleans -
[a0, a1, b0]— given thata0,a1andb0are all the same objects of user-defined typesome_type, this would be array of user-defined typesome_type
|
Warning
|
Mixing multiple different types in a single array literal
would trigger a compile-time error, for example, this is illegal: [1,
"foo"]
|
6.3. Operators
Literals can be connected using operators to make meaningful
expressions. Operators are type-dependent: for example, the +
operator applied to two integers would mean arithmetic addition, while the same operator
applied to two strings would mean string concatenation.
6.3.1. Arithmetic operators
Can be applied to integers and floats:
-
a + b— addition -
a - b— subtraction -
a * b— multiplication -
a / b— division -
a % b— modulo; note that it’s not a remainder:-5 % 3is1, not-2; the result is undefined for negativeb.
|
Note
|
If both operands are integers, the result of an arithmetic operation is
an integer, otherwise it is a floating point number. For example, that
means that 7 / 2 is 3, and 7 / 2.0 is 3.5.
|
Can be applied to strings:
-
a + b— string concatenation
6.3.2. Relational operators
Can be applied to integers, floats and strings:
-
a < b— true ifais strictly less thanb -
a <= b— true ifais less or equal thanb -
a > b— true ifais strictly greater thanb -
a >= b— true ifais greater or equal thanb
Can be applied to integers, floats, strings, booleans and enums (does proper string value comparison):
-
a == b— true ifais equal tob -
a != b— true ifais not equal tob
6.3.3. Bitwise operators
Can only be applied to integers.
-
a << b— left bitwise shift -
a >> b— right bitwise shift -
a & b— bitwise AND -
a | b— bitwise OR -
a ^ b— bitwise XOR
6.3.4. Logical (boolean) operators
Can be only applied to boolean values.
-
not x— boolean NOT -
a and b— boolean AND -
a or b— boolean OR
6.3.5. Ternary (if-then-else) operator
If condition (must be boolean expression) is true, then if_true
value is returned, otherwise if_false value is returned:
condition ? if_true : if_false
// Examples
code == block_type::int32 ? 4 : 8
"It has a header: " + (has_header ? "Yes" : "No")|
Note
|
It is acceptable to mix:
|
|
Caution
|
Using the ternary operator inside a KSY file (which must remain a valid YAML
file) might be tricky, as some YAML parsers do not allow colons ( To ensure maximum compatibility, put quotes around such strings, i.e: |
6.4. Methods
Just about every value in expression language is an object (including
literals), and it’s possible to call methods on it. The common syntax
to use is obj.method(param1, param2, …), which can be abbreviated
to obj.method if no parameters are required.
Note that when the obj in question is a user-defined type, you can
access all its attributes (both sequence and instances) using the same
obj.attr_name syntax. One can chain that to traverse a
chain of substructures: obj.foo.bar.baz (given that obj is a
user-defined type that has a foo field, which points to a user-defined
type that has a bar field, and so on).
There are a few pre-defined methods that form a kind of "standard library" for expression language.
6.4.1. Integers
| Method name | Return type | Description |
|---|---|---|
|
String |
Converts an integer into a string using decimal representation |
6.4.2. Floating point numbers
| Method name | Return type | Description |
|---|---|---|
|
Integer |
Truncates a floating point number to an integer |
6.4.3. Byte arrays
| Method name | Return type | Description |
|---|---|---|
|
Integer |
Number of bytes in the array |
|
String |
Decodes (converts) a byte array encoded using the specified |
6.4.4. Strings
| Method name | Return type | Description |
|---|---|---|
|
Integer |
Length of a string in number of characters |
|
String |
Reversed version of a string |
|
String |
Extracts a portion of a string between character at offset |
|
Integer |
Converts a string in decimal representation to an integer |
|
Integer |
Converts a string with a number stored in |
6.4.5. Enums
| Method name | Return type | Description |
|---|---|---|
|
Integer |
Converts an enum into the corresponding integer representation |
6.4.6. Booleans
| Method name | Return type | Description |
|---|---|---|
|
Integer |
Returns |
6.4.7. User-defined types
All user-defined types can be queried to get attributes (sequence
attributes or instances) by their name. In addition to that, there are
a few pre-defined internal methods (they all start with an underscore
_, so they don’t clash with regular attribute names):
| Method name | Return type | Description |
|---|---|---|
|
User-defined type |
Top-level user-defined structure in current file |
|
User-defined type |
Structure that produced this particular instance of user-defined type |
|
Stream |
Stream associated with this object of user-defined type |
6.4.8. Array types
| Method name | Return type | Description |
|---|---|---|
|
Array base type |
Gets first element of the array |
|
Array base type |
Gets last element of the array |
|
Integer |
Number of elements in the array |
|
Array base type |
Gets the minimum element of the array |
|
Array base type |
Gets the maximum element of the array |
6.4.9. Streams
| Method name | Return type | Description |
|---|---|---|
|
Boolean |
|
|
Integer |
Total size of the stream in bytes |
|
Integer |
Current position in the stream, in bytes from the beginning of the stream |
7. Advanced techniques
7.1. Advanced switching
7.1.1. Switching over strings
One can use type switching over other comparable values,
not just integers. For example, one can switch over a string value. Note
that the left side (key) of a cases map is a full-featured Kaitai Struct expression,
thus all we need is to specify a string. Don’t forget that there’s
still YAML syntax that might get in a way, so we effectively need to
quote strings twice: once for Kaitai Struct expression language, and once in the
YAML representation to save these quotes from being interpreted by
a YAML parser, i.e.:
seq:
- id: rec_type
type: strz
- id: body
type:
switch-on: rec_type
cases:
'"KETCHUP"': rec_type_1
'"MUSTARD"': rec_type_2
'"GUACAMOLE"': rec_type_3If the target language allows switching over strings, it will be rendered
as a switch-style statement, or, if it does not, ksc will fall back to an
if-based rendition.
7.1.2. Switching over enums
One can switch over enums as well. To match against enum values, you would
have to specify enum literals (i.e. enum_name::some_value). Since
there are colons in them, we’ll have to use YAML quotes again:
seq:
- id: rec_type
type: u2
enum: media
- id: body
type:
switch-on: rec_type
cases:
'media::cdrom': rec_type_1
'media::dvdrom': rec_type_2
'media::cassette': rec_type_37.1.3. FourCC
Quite a few formats (like TIFF, RIFF, AVI, etc) use a "FourCC" to switch over in a typical TLV implementation. "FourCC" (which stands for "four character code") is essentially a 4-byte value, which is often made human-readable to aid debugging. It’s usually tempting to read a fixed-size string from the stream and match it against a list of strings:
seq:
- id: fourcc
type: str
size: 4
encoding: ASCII
- id: len
type: u4
- id: body
size: len
type:
switch-on: fourcc
cases:
'"RGB2"': block_rgb2
'"RLE4"': block_rle4
'"RLE8"': block_rle8However, this is generally a bad idea:
-
Reading and matching strings is slow. At least it’s much slower than reading a single 4-byte integer (because it often involves multiple copying of data, encoding checks / conversions, etc). The whole point of using 4-byte FourCC originally was to provide a fast way to read it in single operation.
-
It’s hard to provide an encoding for such a string. Quite a few formats introduced non-ASCII FourCC values, and, even if all current values are ASCII-safe, there’s no guarantee that there would be no weird values like
C6 A2 ED 39in future.
The recommended way to handle FourCC-style types is by using an enum:
seq:
- id: fourcc
type: u4le
enum: pixel_formats
- id: len
type: u4
- id: body
size: len
type:
switch-on: fourcc
cases:
'pixel_formats::rgb2': block_rgb2
'pixel_formats::rle4': block_rle4
'pixel_formats::rle8': block_rle8
enums:
pixel_formats:
0x32424752: rgb2
0x34454C52: rle4
0x38454C52: rle8This runs as fast as it was originally intended, and it provides an extra benefit of allowing more verbose FourCC value descriptions.
7.2. Do nothing
In some rare cases, you need a type that actually does absolutely nothing. For example, you purposely want to ignore parsing a certain switch case and avoid running it through the default type, e.g. a situation like this:
seq:
- id: rec_type
type: u4
- id: body
type:
switch-on: rec_type
cases:
1: rec_type_1
2: rec_type_2
3: dummy # <= must ignore rec_type=3!
_: rec_type_othersThis is very easy to achieve. Here are a few examples of type definitions which do nothing when invoked:
types:
# One can use empty JSON object syntax to avoid specifying any of
# `seq`, `instances`, etc, sections.
dummy_1: {}
# One can use explicit doc to note that there's nothing there.
dummy_2:
doc: This type is intentionally left blank.
# One can use empty `seq` or `instances` or `types` section, any
# other empty sections, or any combination of thereof.
dummy_3:
seq: []
instances: {}
types: {}
# One can use a very explicit notion of the fact that we want to parse 0 bytes.
dummy_4:
seq:
- id: no_value
size: 07.3. Advanced delimited structures
Delimited structures, having terminator
specified to define a structure of arbitrary size, are pretty common
and useful. However, sometimes you’re dealing with more advanced
versions of these which require you to fine-tune certain aspects of
delimiting.
7.3.1. Terminator: consume or include?
What happens with the terminator byte itself, when you’re defining a delimited structure? Normally, terminator is not needed inside your structure, it’s an external entity. For example, if you’re parsing dot-delimited strings, you don’t want these strings to contain the dot:
KSY
|
Input and output
66 6f 6f 2e 62 61 72 2e = "foo.bar." str1 = "foo" str2 = "bar" |
But sometimes you indeed want that dot, and it should be part of the
output. This is possible by specifying include: true
(the default is false):
KSY
|
Input and output
66 6f 6f 2e 62 61 72 2e = "foo.bar." str1 = "foo." str2 = "bar." |
Or sometimes your terminator is actually part of a following structure,
and you don’t want it to be consumed — you want the next structure to
start with that terminator byte. This is possible with
consume: false (which is true by default):
KSY
|
Input and output
66 6f 6f 2e 62 61 72 2e = "foo.bar." str1 = "foo" the_rest = ".bar." |
7.3.2. Ignoring errors in delimited structures
Delimited structures actually can be pretty scary: if we read until the terminator is encountered, what will happen if we never find one? In raw C, a typical answer is a "segmentation fault" occurring in the operation that deals with such strings due to runaway reads past the buffer, i.e. a very bad thing and a big security hole.
In Kaitai Struct, however, you can control this behavior. By default, if you parse a structure awaiting a terminator, and that terminator never happens, you’ll get a clear error / exception similar to "attempted to read past end of stream".
In some cases, you
really want to read until the end of the stream, and this should be
considered normal encoding, not an error. For these cases, you can
specify eos-error: false (the default is true):
seq:
- id: my_string
type: str
terminator: 0
eos-error: false
encoding: UTF-8This structure will read both terminated and non-terminated strings successfully, without triggering an error:
61 62 63 00 64 65 66 => my_string = "abc" 61 62 63 00 => my_string = "abc" 61 62 63 => my_string = "abc"
7.4. Importing types from other files
As your project grows in complexity, you might want to have multiple
.ksy files: for example, for different file formats, structures,
substructures, or to reuse the same subformat in several places. As in most
programming languages, Kaitai Struct allows you to have multiple
source files and has imports functionality for that.
Using multiple files is very easy. For example, if you have a
date.ksy file that describes the date structure:
meta:
id: date
seq:
- id: year
type: u2le
- id: month
type: u2le
- id: day
type: u2leand you want to use it in a file listing specification
filelist.ksy, here’s how to do that:
meta:
id: filelist
# this will import "date.ksy"
imports:
- date
seq:
- id: entries
type: entry
repeat: eos
types:
entry:
seq:
- id: filename
type: strz
encoding: ASCII
# just use "date" type from date.ksy as if it was declared in
# current file
- id: timestamp
type: date
# you can access its members too!
- id: historical_data
size: 160
if: timestamp.year < 1970Generally, you just add an array in meta/imports and list all you
want to import there. There are 2 ways to address the files:
- Relative
-
Uses a path given as a relative path to the file, starting with the same directory in which the main .ksy file resides. This is useful to include files in the same directory or to navigate to somewhere in your project. Examples include:
foo,foo/bar,../foo/bar/baz, etc. - Absolute
-
Looks like
/fooor/foo/bar(i.e. starting with a slash), and searches for the given .ksy file in module search path(s). This is usually used for modules from centralized repositories / ksy libraries. Module search paths are determined by (in order of decreasing priority):-
Paths given using the command-line
-Iswitch. -
Paths given using a
KSPATHenvironment variable (multiple paths can be specified separated with:on Linux/OS X and with;on Windows) -
Default platform-dependent search paths, determined at compiler build time and/or during installation
-
|
Note
|
In the Web IDE you obviously don’t have environment variables and command-line switches, so absolute path imports are used to reference modules in the preloaded "kaitai.io" library. |
|
Caution
|
Please use only forward slashes / in import paths for
consistency. Kaitai Struct will convert them automatically to the proper
platform-dependent path separator (/ or \).
|
7.5. Opaque types: plugging in external code
Sometimes you want Kaitai Struct-generated code to call code in your application to do the parsing, for example, to parse some text- or state-based format. For that, you can instruct ksc to generate code with so-called "opaque" types.
Normally, if the compiler encounters a type which is not declared either in the current file or in one of the imported files, for example:
meta:
id: doc_container
seq:
- id: doc
type: custom_encrypted_object... it will output an error:
/seq/0: unable to find type 'custom_encrypted_object', searching from doc_container
If we want to provide our own implementation of a
custom_encrypted_object type, first we need to compile our .ksy file
with the --opaque-types=true option. This will avoid the error, and the
compiler will consider all unknown types to be "opaque", i.e. it will treat
them as existing in some external space.
Alternatively, instead of specifying the command line argument
--opaque-types=true to the compiler, as of Kaitai Struct version 0.7,
it is now possible to specify meta field ks-opaque-types as follows:
meta:
id: doc_container
ks-opaque-types: true
seq:
- id: doc
type: custom_encrypted_object|
Note
|
Of course, the compiler doesn’t know anything about opaque types, so trying to access any attributes of it (i.e. using expression language) will fail. |
This will generate the following code (for example, in Java):
public class DocContainer extends KaitaiStruct {
// ...
private void _read() {
this.doc = new CustomEncryptedObject(this._io);
}
}As you see, CustomEncryptedObject is instantiated here with a single
argument: an IO stream. All that’s left is to create a class with a
compatible constructor that will allow a call with a single
argument. For statically typed languages, note that the constructor’s
argument is of type KaitaiStream.
An example of what can be done (in Java):
public class CustomEncryptedObject {
byte[] buf;
public CustomEncryptedObject(KaitaiStream io) {
// read all remaining bytes into our buffer
buf = io.readBytesFull();
// implement our custom super Caesar's cipher
for (int i = 0; i < buf.length; i++) {
byte b = buf[i];
if (b >= 'A' && b <= 'Z') {
int letter = b - 'A';
letter = (letter + 7) % 26;
buf[i] = (byte) (letter + 'A');
}
}
}
}|
Tip
|
Alternatively, opaque types can be (ab)used to connect several Kaitai Struct-generated types together without importing. If one type instantiates another, but does not use it in any other way (i.e. doesn’t access its inner attributes using expression language), one can just compile two .ksy files separately, throw them into the same project and they shall use each other without a problem. |
7.6. Custom processing routines
|
Important
|
Feature available since v0.8. |
As discussed in Processing: dealing with compressed, obfuscated and encrypted data, Kaitai Struct utilizes the process key to
invoke processing of the data for the purposes of "bytes in - bytes
out" transformations. It is meant to be used to implement compression &
decompression, encryption & decryption, obfuscation & de-obfuscation,
those kind of transformations.
Kaitai Struct runtime libraries come bundled with a "standard" set of such transformations, but quite often one encounters the need to implement some custom data transformation algorithm. There are many thousands of encryption and compression algorithms. It’s impractical to both try to implement them in declarative form using standard Kaitai Struct types (because as an end-user, you’re most likely interested in the decoded result, not internal structures of the algorithm/cipher), and it’s next to impossible to bundle all the data processing algorithms in the world into Kaitai Struct runtime (not only it would become very bloated, but also quite a few such algorithms are encumbered by software patents and licensing restrictions).
To alleviate this problem, Kaitai Struct allows one to invoke custom
processing algorithms, implemented in imperative code in target
languages. This works very similar to opaque external
types, but for process invocations, not for type
invocations.
Calling a custom process type is easy:
seq:
- id: key
type: s4
- id: buf
size: 50
process: my_custom_processor(key)This would generate something like this (example is for Java, other target languages a use similar technique):
// Reads 50 bytes to process.
this._raw_buf = this._io.readBytes(50);
// Initializes processor object, passing every argument specified in
// `process` key into constructor
MyCustomProcessor _process__raw_buf = new MyCustomProcessor(key());
// Invokes `decode(...)` method, passing unprocessed byte array,
// expecting it to return a processed one.
this.buf = _process__raw_buf.decode(this._raw_buf);A typical implementation of a custom processor would look like this (again, example in Java; refer to language-specific notes for documentation on other languages):
import io.kaitai.struct.CustomDecoder;
public class MyCustomProcessor implements CustomDecoder {
private int key;
public CustomFx(int key) {
this.key = key;
}
@Override
public byte[] decode(byte[] src) {
// custom "bytes in -> bytes out" processing routine
byte[] dst = new byte[src.length];
for (int i = 0; i < src.length; i++) {
dst[i] = (byte) (src[i] + key);
}
return dst;
}
}This example is mostly self-explanatory. Strongly typed languages, such
as Java, usually provide some sort of interface that such a custom
processor class should implement. For Java, it’s named
CustomDecoder. And, as outlined there, we implement:
-
a custom constructor, which accepts the encoding parameters (like keys, etc), as specified in a ksy
-
a
decode(byte[] src)method which decodes a given byte array — in this particular example, it just adds whatever we supplied as "key" to every byte
|
Note
|
decode can return a different number of bytes than it is
given. This is perfectly normal, for example, with decompression.
|
By default, specifying a plain name invokes a custom processing class in the same namespace/package where the code is generated. If you want to keep your generated code in a separate namespace/package than your custom hand-made code, you can specify it like this:
seq:
- id: buf
size: 50
process: com.example.my_rle(5, 3)For Java, this would result in an invocation of com.example.MyRle
class. Other languages use similar rules of translation; see
language-specific notes for details.
A special namespace prefix "kaitai." is reserved for extended libraries provided by the Kaitai project. As of 0.8, none of these have been published, but in future you can expect implementations like "kaitai.crypto.aes" or "kaitai.compress.lzma" to be provided by libraries implemented in multiple languages that would be released along with the minimal core Kaitai Struct runtime.
7.7. Enforcing parent type
Every object (except for the top-level object) in a .ksy file has a parent, and that parent has a type, which is some sort of user-defined type. What happens if two or more objects use the same type?

types:
opcode_jmp:
seq:
- id: target
type: arg
opcode_push:
seq:
- id: value
type: arg
arg:
seq:
- id: arg_type
type: u1
- id: arg_value
type: u1In this example, both opcodes use same type arg. Given that these
are different types, Kaitai Struct infers that the only thing they have in common
is that they are objects generated by Kaitai Struct, and thus they
usually implement KaitaiStruct API, so the best common type that will
be ok for both parents is KaitaiStruct. Here’s how it looks in any
statically-typed language, e.g. in Java:
public static class OpcodeJmp extends KaitaiStruct {
// ...
private void _read() {
this.target = new Arg(this._io, this, _root);
}
// ...
}
public static class OpcodePush extends KaitaiStruct {
// ...
private void _read() {
this.value = new Arg(this._io, this, _root);
}
// ...
}
public static class Arg extends KaitaiStruct {
public Arg(KaitaiStream _io, KaitaiStruct _parent, TopLevelClass _root) {Note that both OpcodeJmp and OpcodePush supply this as _parent
argument in Arg constructor, and, as it is declared as
KaitaiStruct. As both opcode classes are declared with extends
KaitaiStruct, this code will compile properly.
7.7.1. Replacing parent
In some situations, you might want to replace the default this
passed as _parent with something else. In some situations this will
provide you a clean and elegant solution to relatively complex
problems. Consider the following data structure that loosely
represents a binary tree:
types:
tree:
seq:
- id: chunk_size
type: u4
- id: root_node
type: node
node:
seq:
- id: chunk
size: ??? # <= need to reference chunk_size from tree type here
- id: has_left_child
type: u1
- id: has_right_child
type: u1
- id: left_child
type: node
if: has_left_child != 0
- id: right_child
type: node
if: has_right_child != 0Everything is pretty simple here. The main tree type has chunk_size
and a root_node, which is of node type. Each individual node of
this tree carries a chunk of information (of a size determined in the tree
type), some flags (has_left_child and has_right_child) and then
calls itself again to parse either left or right child nodes for the
current node if they exist, according to the flags.
The only problem is how to access chunk_size in each node. You can’t
access the tree object starting from _root here, as there could be many
different trees in our file, and you need to access the current one. Using
_parent directly is just impossible. True, given that node type is
used both by tree and node itself, it got two different parents,
so Kaitai Struct compiler downgrades node’s parent type to
KaitaiStruct, thus trying to access _parent.chunk_size would result
in a compile-time error.
TODO: add more about the error
This situation can be resolved easily by using parent overriding. We modify our code this way:
types:
tree:
seq:
- id: chunk_size
type: u4
- id: root_node
type: node
node:
seq:
- id: chunk
size: _parent.chunk_size # <= now one can access `tree` with _parent
- id: has_left_child
type: u1
- id: has_right_child
type: u1
- id: left_child
type: node
parent: _parent # <= override parent to be be parent's parent
if: has_left_child != 0
- id: right_child
type: node
parent: _parent # <= override parent here too
if: has_right_child != 0We’ve changed only three lines. We’ve enforced the parent of the node in the
left_child and right_child attributes to be passed as _parent,
not this. This, effectively, continues passing a reference to the original
node’s parent, which is a tree type object, over and over in the whole
recursive structure. This way one can access the structure’s root by just
using _parent. Naturally, we’ve done exactly that to get ourselves
chunk_size by just using size: _parent.chunk_size.
7.7.2. Omitting parent
In some cases, you want some object to have no parent at all. The primary use case for this is to make sure that some instantiation of it does not affect the parent type. In many cases, resorting to this method is a sign that you need to stop and rethink your design, but for some formats, it’s unavoidable and in fact simplifies things a lot.
To omit parent (i.e. pass a null reference or something similar as a
parent), use parent: false.
|
Note
|
Language design explanation: while it might seem logical to specify
|
TODO: an example where omitting the parent comes useful
7.8. Typecasting
|
Important
|
Feature available since v0.7. |
Kaitai Struct always tries its best to infer all the types automatically, but in some cases it would be impossible to do so in compile-time. For example, there could be some extra conditions known to the format developer, but not to Kaitai Struct.
Consider this example — a typical image format, implemented as Typical TLV implementation (switching types on an expression), which includes a variable number of self-describing sections:
seq:
- id: num_sections
type: u4
- id: sections
type: section
repeat: expr
repeat-expr: num_sections
types:
section:
seq:
- id: sect_type
type: u1
- id: len
type: u4
- id: body
size: len
type:
switch-on: sect_type
cases:
1: sect_header
2: sect_color_data
# ...
sect_header:
seq:
- id: width
type: u4
- id: height
type: u4After that, a bitmap follows, and its size is to be derived as width
* height, as described in the sect_header section. In addition to that,
we’re 100% sure (due to format constraints) that the body of sections[7]
is always sect_header. How do we access width and height in it?
A naïve solution like this won’t compile:
- id: bitmap
size: sections[7].body.width * sections[7].body.heightreporting the following error:
/seq/2/size: don't know how to call anything on AnyType
The reason for that is that from the root type perspective, all section
bodies are alike, and in a strongly typed language, it’s impossible to
guarantee that sections[7].body would be the type we want, and that
type would have width and height attributes. Not only that, but
actually, given that we’ve specified a size attribute, a body could
be just a raw byte array, and not even a user type. Thus, Kaitai Struct decided
that it could be AnyType — a type that can include anything.
The best solution would be to enforce our knowledge using an explicit
typecast with the .as<…> expression operator:
- id: bitmap
size: sections[7].body.as<sect_header>.width * sections[7].body.as<sect_header>.heightTo make it prettier, one can extract
sections[7].body.as<sect_header> using a named value instance:
# ...
- id: bitmap
size: header.width * header.height
instances:
header:
value: sections[7].body.as<sect_header>|
Caution
|
Of course, if our assumption about sections[7] doesn’t come
true in run time, things will go bad. You can expect most languages to
throw a typecasting exception on a failed casting attempt, but in very
low-level languages, such as C++ with RTTI disabled, this would result
in data accessed using wrong offsets, and that could potentially lead
to a crash / segfault / security problem.
|
7.9. Calculated default endianness
|
Important
|
Feature available since v0.8. |
Most formats (like zip, gif, and many others) stick to a single fixed endianness: they always use either big-endian or little-endian integers. Usually this stems from the architecture where the format was developed: the format is relatively easy and quick to parse on its "native" architecture, but requires some extra operations (and parsing time) on non-native architectures.
Some formats (like ELF or Mach-O), however, take an alternative approach: they come in two versions, with big-endian integers and little-endian integers, and they add some sort of header field that helps to distinguish between the two.
To help in implementing such formats, Kaitai Struct supports the concept of
calculated endianness. Instead of using endian: be or endian: le,
one can use a switch, similar to the one introduced in
Typical TLV implementation (switching types on an expression). Consider this example of a TIFF file — it begins with either
"II" (0x49, 0x49) to specify little-endian encoding or "MM" (0x4d,
0x4d) to specify big-endian encoding:
meta:
id: tiff
seq:
- id: indicator
size: 2 # first two bytes determines endianness
- id: body
type: tiff_body
types:
tiff_body:
meta:
endian:
switch-on: _root.indicator
cases:
'[0x49, 0x49]': le
'[0x4d, 0x4d]': be
seq:
- id: version
type: u2
# ...
types:
ifd:
# inherits endianness of `tiff_body`In this example, version and all other numeric types without forced
endianness would use endianness determined by a switch expression in
meta/endian of tiff_body. Moreover, this determined endianness
would also be propagated to other subtypes, declared within
tiff_body.
If indicator is neither II nor MM, i.e. both cases fail,
this example would trigger a parsing exception. If you want to handle
it in a manner like "II means little-endian and everything else means
big-endian", use the normal else case (_):
meta:
endian:
switch-on: _root.indicator
cases:
'[0x49, 0x49]': le
_: be7.10. Parametric types
|
Important
|
Feature available since v0.8. |
Consider the following format, which features two similar lists of key-value pairs:
seq:
- id: short_pairs
type: kv_pair_3
repeat: expr
repeat-expr: 0x100
- id: long_pairs
type: kv_pair_8
repeat: expr
repeat-expr: 0x100
types:
kv_pair_3:
seq:
- id: key
size: 3
type: str
- id: value
type: strz
kv_pair_8:
seq:
- id: key
size: 8
type: str
- id: value
type: strzThe only difference between kv_pair_3 and kv_pair_8 types is the
length of key. "Short" pairs use a 3-byte long key, and "long" pairs
use an 8-byte key. That’s lots of duplication, and just imagine what
would happen if you need 4-byte keys or 6-byte keys. To alleviate
that, one can declare a so-called "parametric" type, like this one:
types:
kv_pair:
params:
- id: len_key
type: u2
seq:
- id: key
size: len_key
type: str
- id: value
type: strzparams acts like seq, but instead of reading attributes values
from the stream, these attributes are expected to be passed as
parameters when one invokes this type. This is done by specifying
parameter value in brackets after the type name:
seq:
- id: short_pairs
type: kv_pair(3)
repeat: expr
repeat-expr: 0x100
- id: long_pairs
type: kv_pair(8)
repeat: expr
repeat-expr: 0x100Of course, there could be more than one parameter (in which case, they are to be comma-separated), and one can use a variety of types:
seq:
- id: my_number
type: fancy_encrypted_number_format(3, true, [0x03, 0xb7, 0x8f])A type specification in a params definition is slightly different from
normal type specifications in seq or instances. It specifies a pure
concept of "type", as would be used to represent data in a programming
language, without any serialization details (like endianness, sizes,
conversions, encodings, etc). Thus, one can’t use any extra keys to
specify that, but instead one can use:
-
no type or
bytesto specify byte arrays -
strto specify strings -
boolto specify booleans -
structto allow arbitrary KaitaiStruct-compatible user types -
ioto specify KaitaiStream-compatible IO streams -
anyto allow any type (if the target language supports that)
|
Note
|
Parametric types with mandatory parameters can’t be read from a
file directly (as they obviously need parameter values supplied from
somewhere), and thus the typical fromFile(…) helper method is not
available for them.
|
7.11. Repetition index
|
Important
|
Feature available since v0.8. |
For the majority of formats, one doesn’t need to access a loop iteration index. If you have a typical archive file directory, which lists file name, offset of the file body and size of the file body together, just use the object-oriented approach:
seq:
- id: num_files
type: u4
- id: files
type: file_entry
repeat: expr
repeat-expr: num_files
types:
file_entry:
seq:
- id: name
type: strz
- id: ofs_body
type: u4
- id: len_body
type: u4
instances:
body:
pos: ofs_body
size: len_bodyHowever, if your format has some information laid out sparsely, i.e. a
separate table of file sizes and their contents, you can use _index
to access the repetition index and resolve the size from the size array:
seq:
- id: num_files
type: u4
- id: len_files
type: u4
repeat: expr
repeat-expr: num_files
- id: files
size: len_files[_index]
repeat: expr
repeat-expr: num_filesIf a format specifies file offsets and you want to read
the contents of the files present on these offsets, things become
more complicated. You can’t read all the bodies in a single
instance with repetition, because pos used on a repeated attribute
acts as an offset where to start sequentially reading all the items
(see Keys relating to the whole array and to each element in repeated attributes for more info). So we have to wrap the file
body in an extra user type file_body, where we can do the actual
parsing.
However, _index is a "local variable", so we lose access to it
as soon as we enter the subtype file_body. The solution is to
pass _index into file_body using Parametric types:
seq:
- id: num_files
type: u4
# ...
# ... some other data here, might be variable size
# ...
- id: file_names
type: strz
repeat: expr
repeat-expr: num_files
# ...
# ... some other data here, might be variable size
# ...
- id: len_files
type: u4
repeat: expr
repeat-expr: num_files
# ...
# ... some other data here, might be variable size
# ...
- id: ofs_files
type: u4
repeat: expr
repeat-expr: num_files
instances:
file_bodies:
type: file_body(_index) # <= pass `_index` into file_body
repeat: expr
repeat-expr: num_files
types:
file_body:
params:
- id: i # => receive `_index` as `i` here
type: s4
instances:
body:
pos: _parent.ofs_files[i]
size: _parent.len_files[i]A more extreme example is a format that specifies only start offsets, but does not directly specify sizes of the files:
30 00 00 00│70 00 00 00│f0 02 00 00
│ │
0x30 │0x70 │0x2f0
└────────────┘└─────────────┘
file 0 file 1
start 0x30 start 0x70
end 0x70 end 0x2f0
────────── ───────────
size 0x40 size 0x280
In this example, we have N = 3 offsets, which specify N - 1 = 2
sections. Sizes of the sections must be derived as the start of the
following section minus the start of the current section. To do such
a calculation, we can use _index in the expressions:
seq:
- id: num_offsets
type: u4
# Just read offsets normally
- id: ofs_files
repeat: expr
repeat-expr: num_offsets
instances:
file_bodies:
type: file_body(_index)
repeat: expr
repeat-expr: num_offsets - 1
type:
file_body:
params:
- id: i
type: s4
instances:
body:
pos: _parent.ofs_files[i]
size: _parent.ofs_files[i + 1] - _parent.ofs_files[i]In an even more complicated example, we have file names interleaved with offsets. There are N - 1 file names and N offsets:
03 00 00 00 = 3 offsets, 2 files 30 00 00 00 = offset 0x30 66 6f 6f 2e 63 00 = "foo.c", null-terminated string 70 00 00 00 = offset 0x70 62 61 72 2e 63 00 = "bar.c", null-terminated string f0 02 00 00 = offset 0x2f0
In this case we’ll need to do a calculation inside file_entry.
Once we pass the _index from the parent type to it, it’s easy:
seq:
- id: num_offsets
type: u4
- id: first_offset
type: u4
- id: files
type: file_entry(_index) # <= pass `_index` into file_entry
repeat: expr
repeat-expr: num_offsets - 1
types:
file_entry:
params:
- id: i # => receive `_index` as `i` here
type: u4
seq:
- id: name
type: strz
- id: ofs_end
type: u4
instances:
ofs_start:
# Normally we access previous file's end offset and use it as
# our current start offset, but for the very first file we'll
# use special field, as "previous file" does not exist for it.
value: 'i > 0 ? _parent.files[i - 1].ofs_end : _parent.first_offset'
body:
pos: ofs_start
size: ofs_end - ofs_start8. Common pitfalls
This section illustrates problems that are encountered frequently by beginner Kaitai Struct users.
8.1. Specifying size creates a substream
Specifying size (or size-eos, or terminator) while specifying a
user type creates a substream. This will mean that all offsets (pos:
XXX) inside that user type will be (1) relative to that substream’s
beginning, (2) constrained to that substream. For example:
seq:
- id: header
size: 4
- id: block
type: block
size: 4 # <= important size designation, creates a substream
instances:
byte_3:
pos: 3
type: u1
types:
block:
instances:
byte_3:
pos: 3
type: u1Given input 00 01 02 03|04 05 06 07:
-
If
sizeis present, the main type’sbyte_3will be03, andblock.byte_3will be07(due to its allocation in a substream) -
If
sizeis absent, the main type’sbyte_3will be03, andblock.byte_3will be03as well (as it will be reusing the root stream)
Avoiding this pitfall is simple: there are two ways:
-
Avoid creating a substream when it’s not needed (i.e. drop the
sizedesignation) -
Force use of a particular stream in a parse instance with
io: XXX, e.g.:
types:
block:
instances:
byte_3:
io: _root._io # <= thanks to this, always points to a byte in main stream
pos: 3
type: u18.2. Not specifying size does not create a substream
An opposite of the previous pitfall, not specifying size (or size-eos, or terminator)
does not create a substream and thus accessing that element’s IO will
effectively point to the main stream (and thus will be a no-op). In this
example, the idea is to reparse the block region twice with two different
types type1 and type2:
seq:
- id: header
type: strz # some variable-sized field before `block`
- id: block_as_type1
type: type1
size: 16 # <= important, creates a substream
instances:
block_as_type2:
io: block_as_type1._io
pos: 0
type: type2If that size is missing, block_as_type2 will reuse the main
stream and will parse a piece of data from pos: 0, which would likely
be part of header, not the region occupied by block_as_type1.
To avoid this pitfall, always make sure you specify size / size-eos /
terminator when you want a substream to be created.
8.3. Applying process without a size
In all cases, the size of the data to process must be defined (either with
size: … or with size-eos: true), i.e. this is legal (without
process — size takes will be determined by some_body_type, reading
normally from a stream):
seq:
- id: body
type: some_body_typeAnd this is not:
seq:
- id: body
process: xor(0xaa)
type: some_body_type
# will not compile — lacks sizeThis is because most processing algorithms need to know the size of data
to process beforehand, and the final size of some_body_type might be
determined only in run-time, after parsing took place.
8.4. Keys relating to the whole array and to each element in repeated attributes
If you use repetition in an attribute, it’s important to understand which YAML keys refer to the whole array and which affect the individual elements instead. Here’s the list:
Whole array
|
Individual elements
|
If you need some key from one group to "belong" to the other, you have to add an extra user-defined type. Depending on your needs, it may be necessary to either wrap a single item or the entire array in it.
-
To force a key relating to individual elements to apply to the whole array instead: create a user type that wraps the entire array, and apply the key on the attribute which uses this wrapper type.
You can see the example in Repeating until total size reaches limit. There we know just the
sizeof the entire array, but asizekey specified on a field using repetition would mean the size of each item, so it’s necessary to add typefile_entriescontaining the array. Then there’s no problem to create a substream of the total size and put this type into it, because keyssizeandrepeatno longer meet in the same attribute. -
To force a key relating to the entire array to apply to each individual item instead: create a user type that wraps the single element, and apply the key on the attribute of this wrapper with the item type itself.
For instance, the second example in section Repetition index shows an archive file directory with separated file offsets and sizes and we need to read the actual file bodies. We don’t want
posto mean the offset of the array, but the offset of the items, so it’s necessary to wrap the item in its own type.